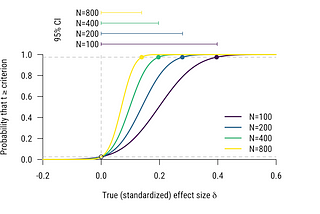
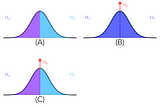
Richard D. MoreyPower and precisionWhy the push for replacing “power” with “precision” is misguided19 min read·Jun 12, 2020--1--1
Richard D. MoreyTo you, on the occasion of your replication crisis“I am very sorry, Pyrophilus…”4 min read·Apr 4, 2020----
Richard D. MoreyNew pre-print: Use of significance test logic by scientists in a novel reasoning taskHow scientists successfully reason about sampling distributions5 min read·Aug 3, 2019----
Richard D. MoreyinTowards Data ScienceWhy you shouldn’t say “this study is underpowered”Ensuring our critiques of power are relevant, clear, and based on good statistics8 min read·Jan 28, 2019--3--3
Richard D. MoreyUse your statistical intuition to save Christmas!A Christmas-themed statistical game and experiment2 min read·Dec 16, 2018--1--1
Richard D. MoreyNotes on “Statistical Inference as Severe Testing” (Tour 1)“Beyond Probabilism and Performance”4 min read·Oct 21, 2018----
Richard D. MoreyAn Open Letter in Support of Markey and ElsonScientists defend two researchers trying to clean up the scientific literature8 min read·Jul 25, 2018--1--1
Richard D. MoreyRedefining statistical significance: the statistical argumentsPart two of a three part series22 min read·Jan 1, 2018--7--7
Richard D. MoreyWhen the statistical tail wags the scientific dogShould we “redefine” statistical significance?4 min read·Nov 26, 2017--3--3